|
Date |
Topics |
Related Materials and
Resources
|
Repositories
|
| 1 |
3/1
|
Introduction to Class
|
|
|
| 2 |
3/8
|
Encoder-Decoder
Review
Attention Model
|
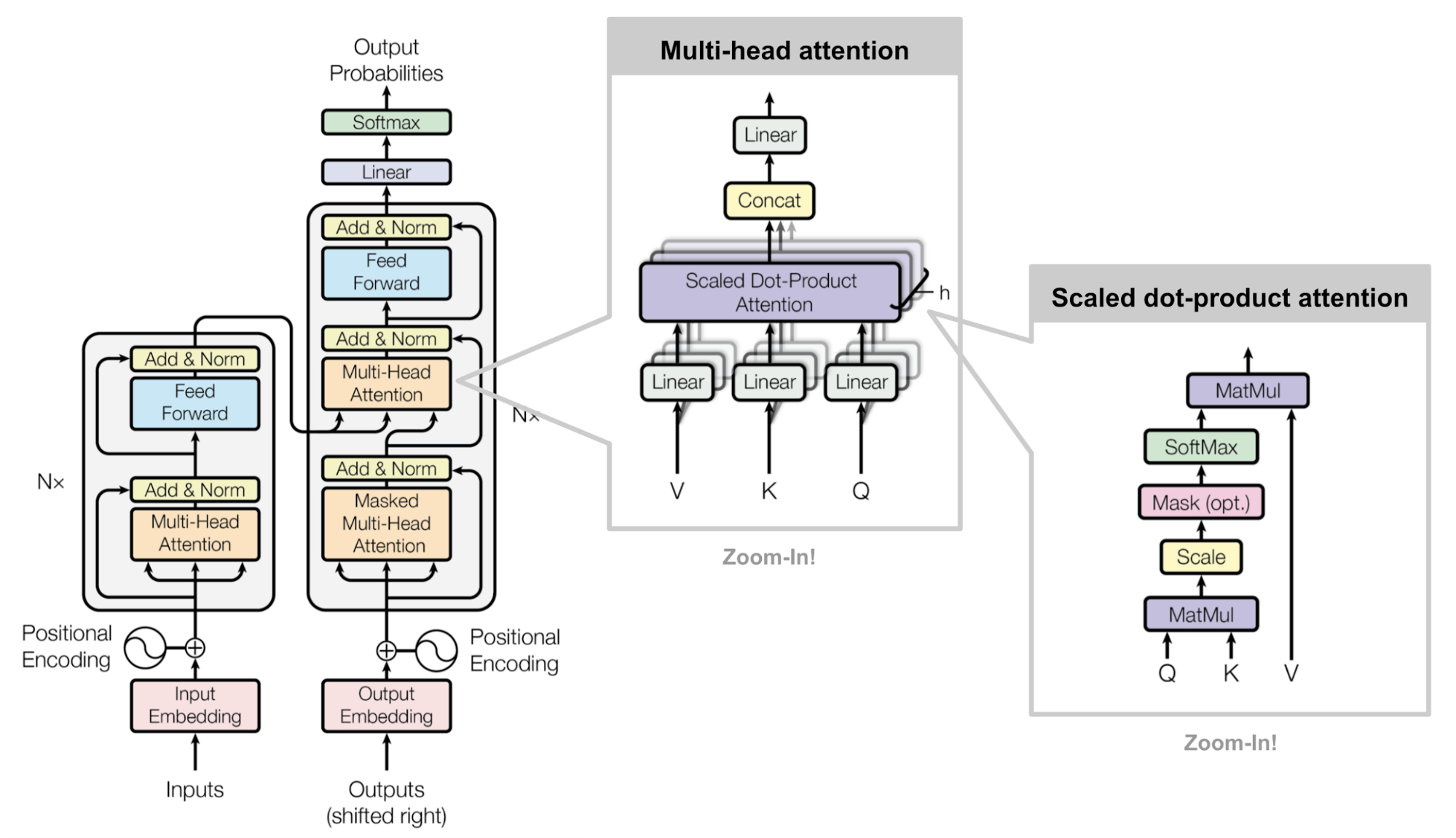
Transformer-based
Encoder-Decoder Models
Attention:
Illustrated Attention
|
PyTorch:
- pytorch-seq2seq
- Sequence to Sequence
Learning with Neural Networks
- Learning Phrase
Representations using RNN Encoder-Decoder
for Statistical Machine Translation
- Neural Machine
Translation by Jointly Learning to Align and
Translate
- Packed Padded Sequences,
Masking, Inference and BLEU
- Convolutional Sequence
to Sequence Learning
- Attention is All You
Need
|
| 3 |
3/15
|
Introduction to
Transformer I
|
Transformers
Explained Visually(Part 1):
Overview of Functionality
Transformers
Explained Visually(Part 2):
How it works, step-by-step
Transformers
Explained Visually(Part3):
Multi-head Attention, deep
dive
Master
Positional Encoding: Part I
|
|
| 4 |
3/22
|
BERT (Bidirectional
Encoder Representations from
Transformers)
|
Bert
Fine-Tuning
BERT Fine-Tuning
Tutorial with PyTorch
BERT Word
Embeddings
|
|
| 5 |
3/29
|
Pre-trained
Models: Designing Effective
Architecture
- Combining
Autoregressive and Autoencoding
Modeling
- Applying
Generalized Encoder-Decoder
|
XLNet:
Generalized Autoregressive Pretraining
for Language Understanding
GLM:
All NLP Tasks Are Generation Tasks: A
General Pretraining Framework
MASS:
Masked Sequence to Sequence
Pre-training for Language
Generation
T5:
Exploring the Limits of
Transfer Learning with a
Unified Text-to-Text
Transformer
BART:Denoising
Sequence-to-Sequence
Pre-training for Natural
Language Generation,
Translation, and
Comprehension
PEGASUS:
Pre-training with Extracted
Gap sentences for
Abstractive Summarization
PALM:
Pre-training an Autoencoding
& Autogressive Language
Model for
Context-conditioned
Generation |
|
6
|
4/5
|
Pre-trained Models:
Designing Effective Architecture
- Cognitive-Inspired
Architectures
- More
Variants of Existing PTMs: Masking Strategy
|
Transformer-XL:
Attentive Language Models Beyond a
Fixed-Length Context
CogQA:
Cognitive Graph for Multi-Hop Reading
Comprehension at Scale
Language
Models as Knowledge Bases?
REALM:
Retrieval-Augmented Language Model
Pre-Training
SpanBERT:
Improving Pre-training by Representing
and Predicting Spans
ERNIE(1.0):
Enhanced Representation through
Knowledge Integration
ERINIE
2.0: A Continual Pre-training Framework
for Language Understanding
ELECTRA:
Pre-training Text Encoders as
Discriminators Rather Than Generators
|
|
7
|
4/12
|
Pre-trained Models:
Utilizing Multi-Source Data
- Multilingual
Pre-Training
|
XLM-R:
Unsupervised Cross-lingual
Representation Learning at
Scale
Unicoder:
A Universal Language Encoder
by Pre-training with
Multiple Cross-lingual Tasks
ViLBERT:
Pretraing Task-Agnostic
Visionlinguistic
Representations for
Vision-and-Language Tasks
Unicoder-VL:
A Universal Encoder for
Vision and Language by
Cross-modal Pre-training
Zero-Shot
Text-to-Image Generation
Learning
Transferable Visual Models
From Natural Language
Supervision
|
|
8
|
4/19
|
Pre-trained Models:
Utilizing Multi-Source Data
- Knowledge-Enchanced
Pre-Training
|
KEPLER:
A Unified Model for
Knowledge Embedding and
Pre-trained Language
Representation
ERNIE(1.0):
Enhanced Representation through
Knowledge Integration
ERINIE
2.0: A Continual Pre-training Framework
for Language Understanding
KnowBERT: Knowledge
Enhanced
Contextual
Word
Representations
KGLM: Using Knowledge-Graphs
for Fact-Aware
Language
Modeling
A
Knowledge-Enhanced
Pretraining Model for
Commonsense Story Generation
Retrieval-Augmented
Generation for
Knowledge-Intensive NLP
Tasks
|
|
9
|
4/26
|
Pre-trained Models:
Improving Computational Efficiency
- System-Level
Optimization
|
Mixed
Precision Training
SwapAdvisor:
Push Deep Learning Beyond
the GPU Memory Limit via
Smart Swapping
Megatron-LM:
Training Multi-Billion
Parameter Language Models
Using Model Parallelism
Train
No Evil: Selective Masking
for Task-Guided Pre-Training
Accelerating
Training of
Transformer-Based Language
Models with Progressive
Layer Dropping
GroupBERT:
Enhanced Transformer
Architecture with Efficient
Group Structures
ALBERT:
A Lite BERT for
Self-supervised Learning of
Language Representations
Compressing
BERT: Studying the Effects
of Weight Pruning on
Transfer Learning
DistilBERT,
a distilled version of BERT:
smaller, faster, cheaper and
lighter
MINILM:
Deep Self-Attention
Distillation for
Task-Agnostic Compression of
Pre-Trained Transformers
TernaryBERT:
Distillation-aware Ultra-low
Bit BERT
|
|
| 10 |
5/3
|
Pre-trained Models:
Interpretation and Theoretical
Analysis
- Knowledge of PTMs:
Linguistic Knowledge
- Knowledge
of PTMs: World Knowledge
- Structural
Sparsity of PTMs
- Theoretical
Analysis of PTMs
|
A
Structural Probe for Finding
Syntax in Word
Representations
Linguistic
Knowledge and
Transferability of
Contextual Representations
What
Does BERT Learn about the
Structure of Language?
Open
Sesame: Getting Inside
BERT's Linguistic Knowledge
Evaluating
Commonsense in Pre-Trained
Language Models
What
BERT is Not: Lessons from a
New Suite of
Psycholinguistic Diagnostics
for Language Models
Is
BERT Really Robust? A Strong
Baseline for Natural
Language Attack on Text
Classification and
Entailment
Trick
Me If You Can:
Human-in-the-loop Generation
of Adversarial Examples for
Question Answering
What
Does BERT Look At? An
Analysis of BERT's Attention
Revealing
the Dark Secrets of BERT
Why
Does Unsupervised
Pre-training Help Deep
Learning?
A
Theoretical Analysis of
Contrastive Unsupervised
Representation Learning
|
|
| 11 |
5/10 |
Introduction to
Huggingface Transformers
- Summary of
Tasks :
Sequence Classification, Extractive
Question Answering, Language
Modeling, Text Generation, Named
Entity Recognition, Summarization,
and Translation
Introduction to Huggingface Transformers
Sentence Embedding with Transformers
|
|
GitHub -
adsieg/text_similarity: Text Similarity
|
| 12 |
5/17 |
Sentence Embedding
with Transformers |
Making
Monolingual Sentence Embeddings Multilingual
using Knowledge Distillation
LaBSE:Language-Agnostic
BERT Sentence Embeddings by Google AI
Billion-scale
Semantic Similarity Search with FAISS+SBERT
How
to Build Semantic Search with Transformers and
FAISS
|
Facebook
Faiss : Library for efficient similarity
search and clustering of dense vectors. |
| 13 |
5/24 |
Search with Transformers
Text
Classification /Generation with Transformers
|
|
txtai
tldrstroy
|
| 14 |
5/31 |
Summarization with
Transformers
Multimodal
Transformers
TAPAS
|
TLDR!!
Summarize Articles and Content With NLP
PEGASUS: Google's State of the Art Abstractive
Summarization Model
Fine Tuning a T5
Transformer for Any Summarization Task
Summarize
Reddit Comments using T5, BART, GPT-2, XLNet
Models
DiscoBERT:
A BERT that Shortens Your Reading Time
Transformers with
Tabular Data: How to Incorporate Tabular Data
with Huggingface Transformers
Google
Unveils TAPAS, a BERT-based Neural Network for
Querying Tables Using Natural Language
Google
TAPAS is a BERT-based Model to Query Tabular
Data Using Neural Language
|
PEGASUS:
Pre-training with Extracted Gap-sentences for
Abstractive Summarization by Zhang et al.
BART:
Denoising Sequence-to-Sequence Pre-training for
Natural Language Generation, Translation, and
Comprehension by Lewis et al.
Language
Models are Unsupervised Multitask Learners by
Radford et al.
Discourse-Aware
Neural Extractive Text Summarization
Multimodal
Transformers | Transformers with Tabular Data
Weakly
Supervised Table Parsing via Pre-training by
Herzig et al.
|
| 15 |
6/7 |
QA with Transformers
Final Presentations
|
BERT-based
Cross-Lingual Question Answering with DeepPavlov
How
to Finetune mT5 to Create a Question
Generator(for 100_Languages)
Build
an Open-Domain Question-Answering System With
BERT in 3 Lines of Code
Sentence2MCQ
using BERT Word Sense Disambiguation and T5
Transformer
|
Haystack: Neural
Question Answering at Scale |